迁移至 400G/800G:第一部分
立即开始规划应对未来数据中心挑战。解读以太网发展路线图。
跨数据中心发展方向再次发生转变。
云基础设施和服务的采用加速,迫切需要增加带宽、加快速度以及缩短延迟。先进的交换机和服务器技术迫使综合布线和架构做出调整。无论设施属于哪一个市场,也不论关注的焦点是什么,都需要考虑企业或云架构变化,这些变化很可能成为满足新要求的必要条件。这意味着,务必了解推动云基础设施和服务采用的趋势,以及辅助组织满足新要求的新兴基础设施技术。以下是制定未来计划期间需要考虑的一些事项。
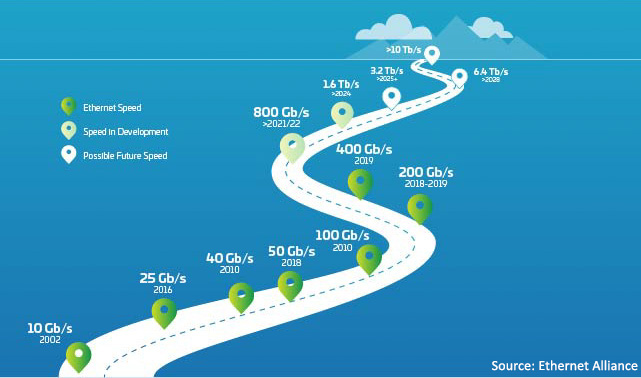
图1:以太网工作规划
您是否想要离线阅读?
下载本文的 PDF 版本,稍后再读。
保持关注最新动态!
订阅企业网络资讯,并在其发布新文章时获取更新。
全球数据使用
毋庸置疑,变化核心围绕全球趋势,重塑消费者期望,迫切需要增加通信以及加快通信速度,例如:
- 社交媒体流量呈爆炸式增长
- 通过大规模小型蜂窝基站致密化全面推广5G服务
- 加速IoT和IIoT(工业IoT)部署
- 从传统办公室工作转向远程工作
超大规模提供商增长
放眼全球,真正的超大规模数据中心可能只有十几家,但对整个数据中心环境造成的影响却颇为可观。根据近期研究结果,仅2020年全球网络在线时间共计12.5亿年。1其中,约53%的通信通过超大规模设施完成。2
与多租户数据中心(MTDC/主机代管)设施建立超大规模合作
随着低延迟性能需求的提升,超大规模和云规模提供商继续致力缩短服务距离,进一步贴近最终用户/终端设备。许多企业与MTDC或主机代管数据中心建立合作,将其服务部署到所谓的网络“边缘”3。如果边缘所处的物理位置较近,缩短延迟及削减网络成本将有助于扩大新型低延迟服务的价值。因此,超大规模领域增长迫使MTDC和主机代管设施调整基础设施和架构,以支持更典型的超大规模数据中心不断扩大的规模,满足持续增长的通信需求。与此同时,这些超大数据中心必须继续灵活满足客户对跨云提供商连接提出的要求。
叶脊和织物网状网络
支持低延迟、高可用性、超高带宽应用绝非超大规模和主机代管数据中心的专属需求。现在,所有数据中心设施必须自我反思,确定能否满足最终用户和利益相关者不断增长的需求。为此,数据中心管理人员纷纷迅速转向光纤更密集的网状结构网络。任意对任意连接、高光纤芯数主干电缆及新连接选项使网络运营商能够在准备过渡到400 Gb/秒4(G)时支持更高的通道速度。
启用人工智能(AI)和机器学习(ML)
此外,部分由IoT和智能城市应用驱动的大型数据中心提供商纷纷采用AI和ML,帮助创建和完善数据模型,实现近实时边缘计算能力。除有望开创新的应用世界(如商用自动驾驶汽车)以外,这些技术还需要具备海量数据集(通常称为数据湖),大规模数据中心计算能力以及足够大的管道,从而根据需要将优化模型推向边缘。5
数据中心经理展望未来时,基于云的演进无处不在。
更多
高性能虚拟服务器
更高
带宽和更低延迟
更快捷
交换机到服务器连接
更高
上行链路/主干速度
快速
扩展能力
着眼于云本身,硬件正在发生变化。传统数据中心通常部署多个不同的网络,现已发展成为采用池化硬件资源和软件驱动管理的高度虚拟环境。在虚拟技术的推动下,需要以最快的方式路由应用程序访问和活动;为此,很多网络管理员不禁会问:“究竟如何设计基础设施,为这些云优先应用提供支持?”
首先需要提高单通道速度。从 25、50 升级到 100G 乃至更高是达到 400G 及以上的关键,现已开始取代传统的 1/10G 迁移路径。不过,除提高通道速度以外,还有很多其他优势。我们必须深入研究。
行业面临拐点。400G 的采用速度增长极快;然而,预计 800G 的采用速度很快将超越 400G。不难想象,关于“推动过渡到 400G 的人员或因素有哪些?”,这个问题并不那么容易回答。面临的因素多种多样,很多因素相互交织。当通道速率增加时,新技术可以降低每比特成本。最新数据显示,100G 通道速率将与八路交换机端口相结合,计划自 2022 年起将 800G 选项推向市场。尽管如此,需要采取多种方式使用这些端口,如 LightCounting 数据6所示,其中 400G 和 800G 主要分解为 4X 100G 或 8X 100G。这种突破性应用正是这些新光学应用的早期推动因素。
图2:数据中心以太网端口传输
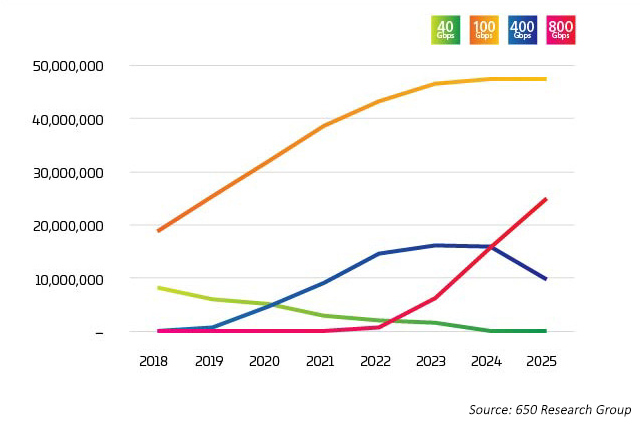
在数据网络中,容量是一个关于服务器、交换机和连接检查和制衡的问题。每一次过渡相互推动,速度更快,费用更低,从而有效跟踪由数据集、AI和ML增长产生的需求。多年来,交换机技术始终是主要瓶颈。随着 Broadcom StrataXGS® Tomahawk® 3 的推出,现在数据中心管理人员可以将交换和路由速度提高至 12.8 太比特/秒(Tb/s),同时将每端口成本降低 75%。Broadcom Tomahawk 4交换机芯片的带宽为25 Tb/s,提升了数据中心行业的整体交换能力,领先于日益增长的AI和ML工作负载。而今,这款芯片支持64个400G端口;但在25.6Tb/s的容量下,半导体技术将引领我们开拓前进:未来,单个芯片可能设置32个800G端口。巧合的是,32也是1U交换机面板上呈现的最大QSFP-DD或OSFP(800G收发器)数量。
现在,CPU处理能力是一项限制因素。对吗?错误。今年早些时候,NVIDIA推出了新型Ampere服务器芯片。事实证明,游戏中使用的处理器非常适合处理AI和ML所需的训练和基于推理的处理。据NVIDIA称,一台基于Ampere的机器可以完成120台Intel驱动服务器开展的工作。
图3:以太网速度
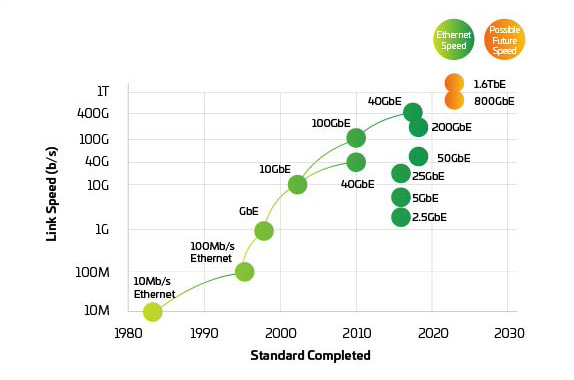
鉴于交换机和服务器应根据需要按计划支持400G和800G端口,因而物理层面临巨大压力,从而保持网络平衡。IEEE 802.3bs于2017年获得批准,为200G和400G以太网的发展铺平了道路。尽管如此,IEEE刚刚完成了800G及以上端口的带宽评估。IEEE成立研究小组以确定400G以上应用的目标,鉴于开发和采用新标准需要一定的时间,我们可能已经滞后了。目前,整个行业正在联合推出800G端口并着手努力实现1.6T及更高目标,同时提高功率并降低每比特成本。
随着为交换 ASIC 提供电力 I/O 的串行器/解串器 (SERDES) 从 10G、25G、50G 逐步迁移,交换速度不断加快。一旦 IEEE80202.3ck 成为认证标准,预计 SERDES 将达到 100G。交换机专用集成电路(ASIC)也在增加 I/O 端口密度(又称基数)。高基数 ASIC 可支持更多的网络设备连接,从而有可能消除层置顶式(ToR)交换机。反过来又可以减少云网络所需的交换机总数。(如果某家数据中心有 100,000 台服务器,可通过 RADIX 两级交换支持512 。)高基数 ASIC 可降低资本支出(交换机更少)、降低运营支出(降低交换机供电和冷却能耗),同时通过缩短延迟提高网络性能。
图4:高基数交换机对交换机带宽的影响
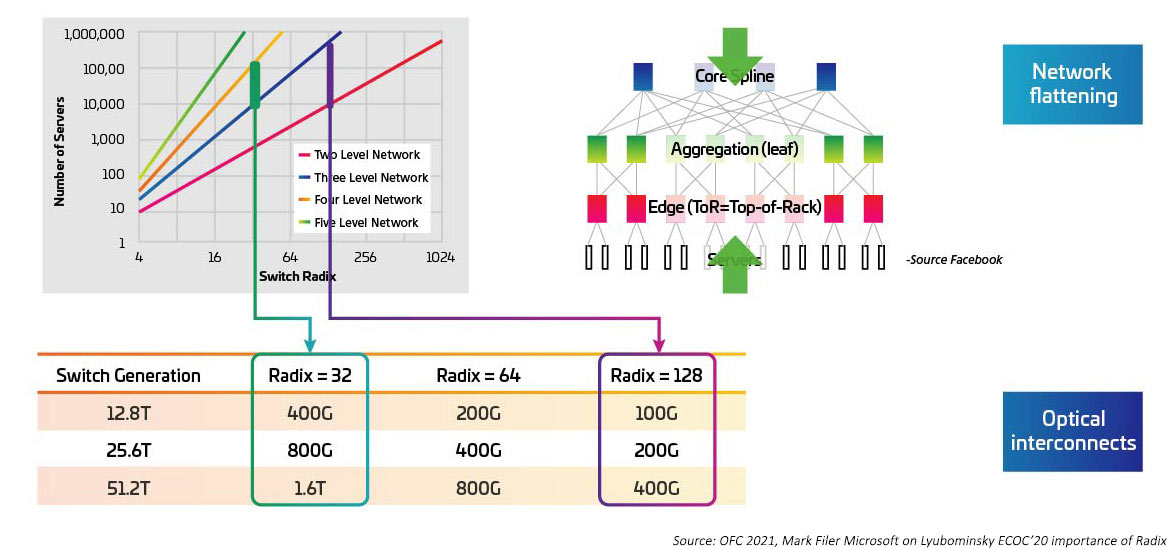
基数和交换速度增加,与此密切相关的是,需从置顶式(ToR)拓扑结构迁移到列中(MoR)或列末(EoR)配置,当简化列内服务器与MoR/EoR交换机的诸多连接时,仍将保留综合布线方法的优势。要利用新型高基数交换机,必需能够以更高的效率管理大量服务器连接。反过来,还需要部署最新光学模块和综合布线,请参考 IEEE802.3cm 标准。IEEE802.3cm 标准享有可插拔收发器的种种优势,适用于大型数据中心的高速服务器网络应用,将八个主机连接定义为一个 QSFP-DD 收发器。
图5:从 ToR 架构过渡到 MoR/EoR 架构
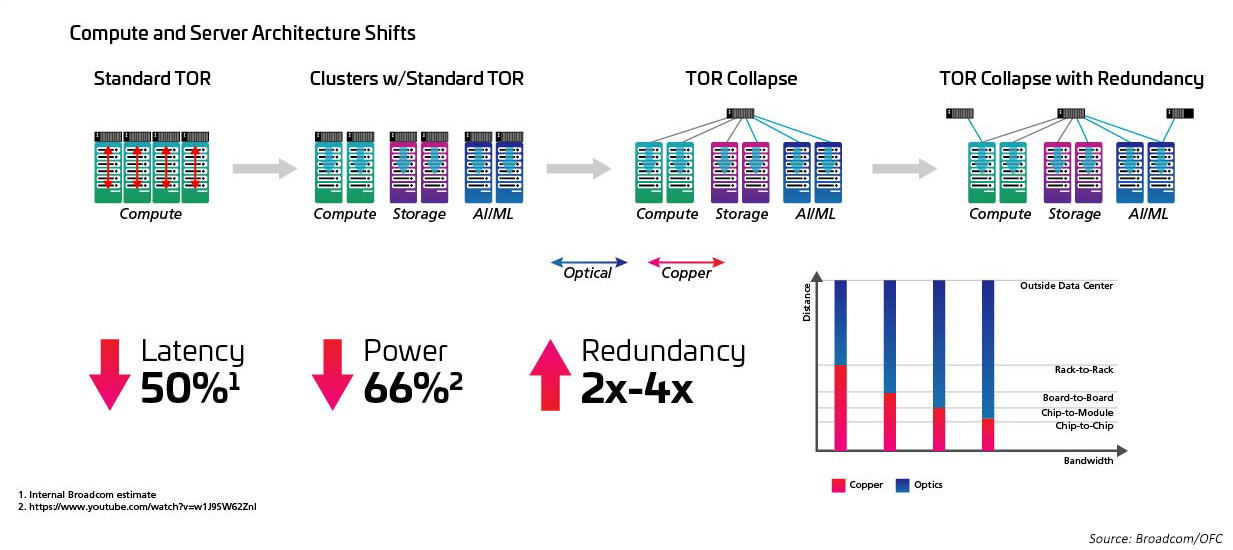
在采用 QSFP28 的情况下,需通过提供高密度和低功耗来推动采用 100G;与此相同,升级到 400G 和800G 也离不开新型收发器的支持和推动。现行的 SFP、SFP+ 或 QSFP+ 光学元件足以实现 200G 链路速度。然而,升级到 400G 需要将收发器密度翻倍。没问题。
QSFP-双密度(QSFP-DD7)和八路(四路的2倍)小型可插拔(OSFP8)多源协议(MSA)支持网络将 ASIC 电力 I/O 连接数量增加一倍。这不仅可以累计提高 I/O 实现更高的聚合速度,还能保证所有 ASIC I/O 连接抵达网络。
具有 32 个 QSFP-DD 端口的 1U 交换机与 256 个(32x8)ASIC I/O 相匹配。通过这种方式,既可以在交换机(8*100 或 800G)之间建立高速链路,也可以在连接服务器时保持最大数量的连接。
最新收发器格式
随着 OEM 纷纷尝试发挥超大规模和和云级数据中心的优势,在成本和性能的驱动下,400G 光学市场逐步发展成熟。2017 年,CFP8 成为第一代 400G 模块,广泛应用于核心路由器和 DWDM 传输客户端接口。CFP8 收发器是 CFP MSA 指定 400G 模块。模块尺寸略小于 CFP2,同时该光学元件支持 CDAUI-16(16x25G NRZ)或CDAUI-8(8x50G PAM4)电力 I/O。带宽密度分别是 CFP 和 CFP2 收发器的8倍和 4 倍。
“第二代” 400G 模块采用 QSFP-DD 和 OSFP。QSFP-DD 收发器向后兼容现有 QSFP 端口。QSFP+(40G)、QSFP28(100G) 和QSFP56(200G)等现有光学模块的成功应用为 QSFP-DD 收发器的推出奠定了基础。
与 QSFP-DD 光学元件一样,OSFP 支持使用八条通道,而不是四条通道。两种类型的模块均支持 1RU 卡(交换机)的 32 个端口。为支持向后兼容性,OSFP 需要配备 OSFP 到 QSFP 适配器。
图6:OSFP 与 QSFP-DD 收发器

调制方案
长期以来,网络工程师一直对 1G、10G 和 25G 使用非归零(NRZ)调制,并使用主机侧前向纠错(FEC)实现远距离传输。为了从 40G 迁移到 100G,行业只需实现 10G/25G NRZ 调制并行化,同时利用主机侧 FEC 延长传输距离。为实现 200G/400G 乃至更高速度,亟需采取新型解决方案。
图7:采用高速调制方案实现 50G 和 100G 技术
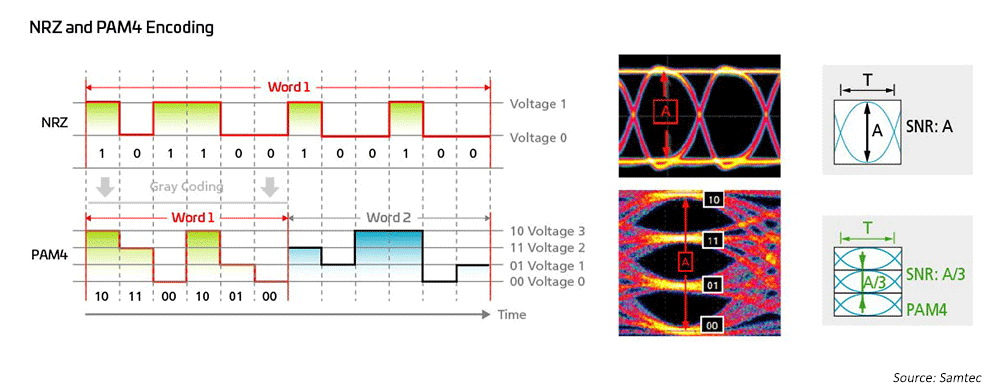
因此,光学网络工程师采用四级脉冲幅度调制(PAM4)实现超高带宽网络架构;PAM4 是针对 400GPAM4 的现行解决方案。它主要基于 IEEE802.3,IEEE802.3 针对多模(MM)和单模(SM)应用新出台了高达 400G(802.3bs/cd/cu)速率的以太网标准。多种分支选项可供选择,从而适应大型数据中心的不同网络拓扑。
调制方案越来越复杂,意味着基础设施必需能够减少回波损耗和衰减。
预测 – OSFP 与 QSFP-DD
关于 OSFP 与 QSFP-DD,目前妄断行业趋势还为时过早;两种模块均已获得各大领先数据中心以太网交换机供应商的支持,而且赢得了大量客户的拥护。或许,企业更喜欢将 QSFP-DD 视为基于 QSFP 的现有光学元件的增强版本。随着 OSFP-XD 的推出,OSFP 似乎推动了这一趋势,通道数量扩展到 16 个,未来计划将通道速率提升至 200G。
QSFP 已成为 100G 及以下模块的首选解决方案,因为 QSFP 的尺寸、功率和成本比双工收发器更具优势。在上述成功的基础之上,QSFP-DD 还提供向后兼容性,允许在采用新型 DD 接口的交换机中使用 QSFP 收发器。
展望未来,很多人认为 100G QSFP-DD 产品将在未来几年大受欢迎。OSFP 技术很可能获得 DCI 光学链路或尤其需要高功率及高光学 I/O 的链路的青睐。据广大 OSFP 拥护者预计,1.6T 和 3.2T 收发器将成为未来的主流。

组合包装光学元件(CPO)是实现 1.6T 和 3.2T 的备选方案。但是,CPO 需要打造全新的生态系统,使光学元件更靠近交换机 ASIC,从而提高速率并降低功耗。光纤互连网络论坛(OIF)正在积极研究这一课题。目前,OIF 正在讨论确定最适合“下一级速率”的技术,很多人认为速率将增加一倍,即达到 200G。增加通道也是一种选择 - 或许可以采用 32 条通道,因为有些人认为究其根本必需增加通道并提高通道速率才能以合理的网络成本持续满足网络需求。
从预测角度而言,唯一可以肯定的是,综合布线基础设施必须具备内置灵活性,才能满足未来网络拓扑和链路需求。尽管长期以来天文学家一直认为“每个光子都很重要”,因为网络设计人员希望将每比特能量降至几pJ/Bit9,但每个级别的守恒都很重要。高性能综合布线将有助于削减网络开销。
交换机不断升级,旨在降低网络成本和功率的同时提供更多高速通道。八路模块允许这些附加链路通过1U交换机的32端口空间建立连接。使用光学模块的通道分支保持较高的基数。
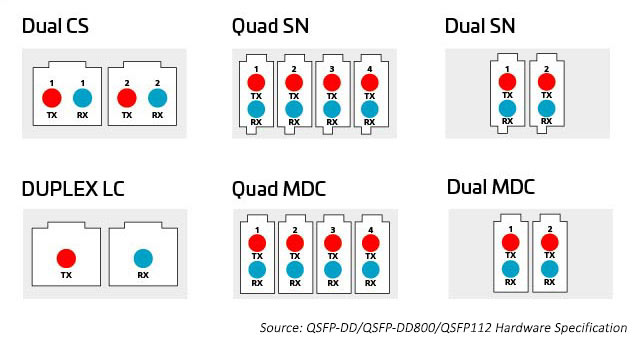
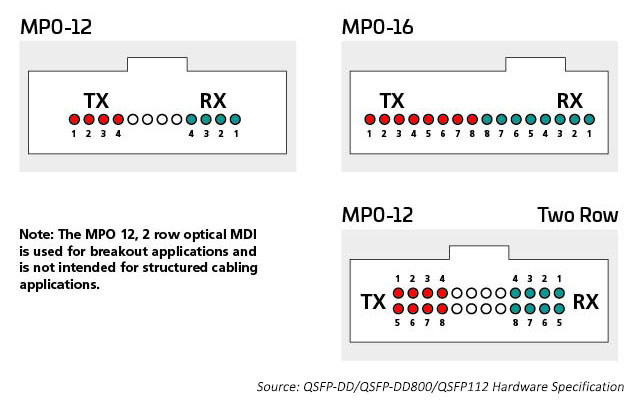
连接器技术方案多种多样,为突破和分配八路模块提供的额外容量提供了更多的选择。连接器包括并行 8、12、 16 和 24 芯光纤多推式(MPO)连接器,以及双工光纤 LC、SN、MDC和CS 连接器。请见下文了解更多信息。
图8:从八进制模块分配容量的选项
MPO 连接器
近年来,在数据中心内连接交换机和服务器的主要方法是围绕 12 或 24 芯光纤进行综合布线,通常使用 MPO连接器。八进制技术(每个交换机端口 8 个交换机通道)的引入使数据中心能够将增加的 ASIC I/O 数量(目前每个交换机 ASIC 256 个)与光端口相匹配。这会产生可用于连接服务器或其他设备的最大 I/O 数量。
光学 I/O 使用适合所用光学通道数量的连接器。一个 400G 收发器可能具有一个带有 400G 光学 I/O 的双工LC连接器,它也可能具有 4 个需要8根光纤的 100G 光学 I/O。MPO12 或 4 个 SN 双工连接器将安装到收发器外壳中,提供此应用所需的 8 根光纤。需要十六根光纤来匹配 8 个电气和光学 I/O,同时保留交换机 ASIC 基数。光纤端口可以是单模,也可以是多模,具体取决于链路设计支持的距离。
例如,多模技术可继续为数据中心的短距离链路提供最具成本效益的高速光学数据速率。IEEE标准支持单链路 400G(802.3 400G SR4.2)技术,该技术使用 4 根光纤传输和 4 根光纤接收,每根光纤承载两个波长。该标准扩展了双向波分复用(BiDi WDM)技术应用范围,这项技术最初用于支持交换机到交换机的链路。该标准使用 MPO12 连接器,是首个使用 OM5 MMF 进行优化的标准。
在需要将许多设备(例如服务器机架)连接到网络的情况下,维护交换机基数非常重要。IEEE 802.3cm 标准(2020)对 400G SR8做出规定,支持使用8根光纤传输和 8 根光纤接收的 8 个服务器连接。该应用已获得云运营商的支持。目前正在部署 MPO-16 架构以优化此解决方案。
单模标准支持长距离应用(例如交换机到交换机)。IEEE 400G-DR4 通过 500 根光纤支持 8 米的覆盖范围。MPO-12 或 MPO-16 可支持此应用。16 芯方法的价值在于增加了灵活性;数据中心管理员可以将 400G 电路划分为可管理的 50/100G 链路。例如,可以断开交换机上的 16 芯光纤连接,支持多达 8 台服务器以 50/100G 的速率连接,同时匹配电气通道速率。MPO 16 芯连接器采用不同的键控方式,以防止与 12 芯 MPO 连接器连接。
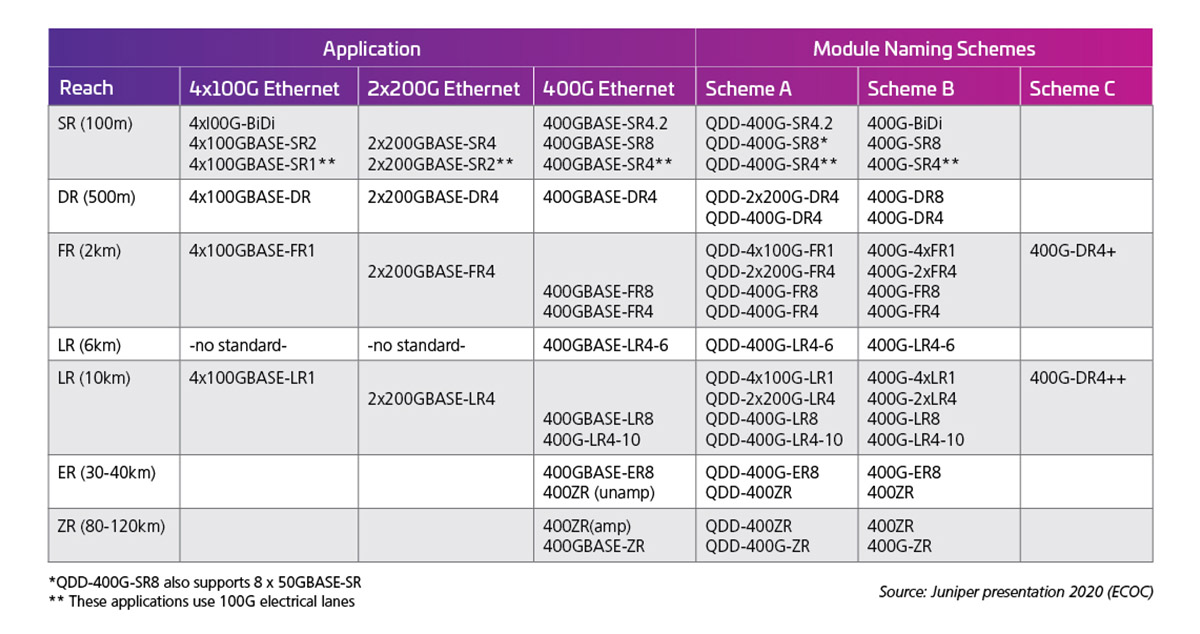
而且,电通道速率决定光接口的输出能力。表1显示了 400G(50G X 8)模块标准/可能性示例。
表1:具有 50G 电气通道的 400G 容量 QSFP-DD
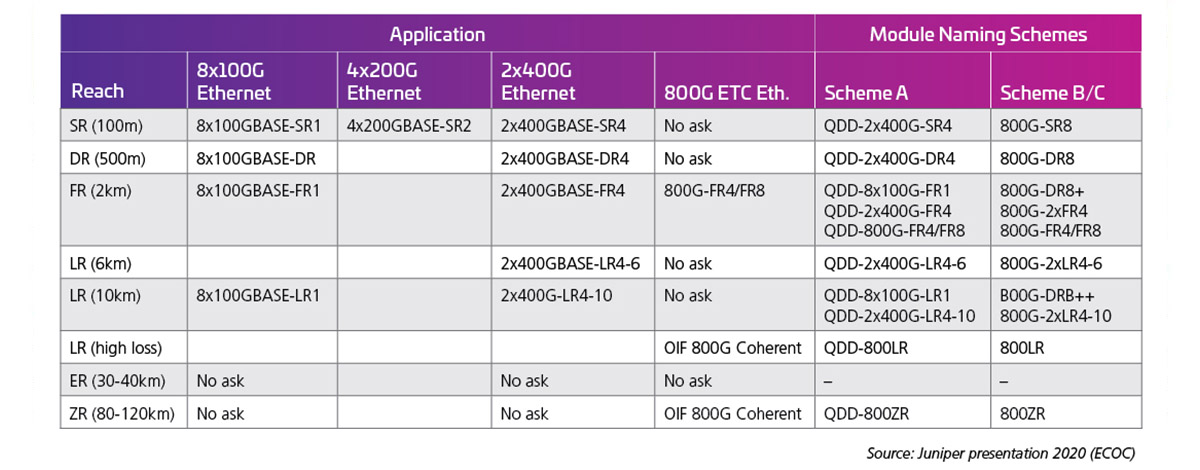
当通道速率翻倍至 100G 时,以下光接口成为可能。在撰写本文时,100G 通道速率标准(802.3 ck)尚未完成;不过,早期产品正在陆续发布,实际上许多可能性即将成为现实。表 2(由 J. Maki(Juniper)在 ECOC 2020 上展示)显示了早期业界对 800G 模块表现出的关注和兴趣。
表 2:具有 100G 电气通道的 800G 容量 QSFP-DD
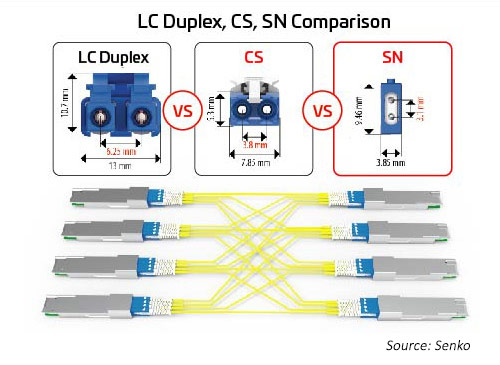
双工连接器
随着通道数量和通道速度的增加,拆分光学 I/O 变得越来越有吸引力。如前所述,八路模块可支持 1、2、4 或 8 个双工链路的连接器选项。所有这些选项都可以与 MPO 连接器配套使用;但是,该选项可能不如单独的双工连接器有效。双工连接器占地面积更小,有助于启用这些选项。SN 是一种极小尺寸(VSFF)双工光纤连接器,适合此类应用。采用 1.25mm 套圈技术,此前 LC 连接器也采用过这项技术。因此,光学性能和强度相同,但目的在于为高速光学模块提供更灵活的分线选项。SN 连接器可为八路收发器模块提供 4 个双工连接。早期应用 SN 主要是为了实现光学模块分线应用。
图10:领先的双工连接器与 400G/800G 迁移的突破应用之间的尺寸关系
连接器速度限制?
连接器通常不决定速度,经济才是决定速度的主因。光学技术最初由服务提供商开发和部署,他们有足够的资金和带宽需求来支持自身发展,以及使用最少量的光纤并采用最经济的方式桥接的长途链路。如今,大多数服务提供商更热衷于将单工或双工连接器技术与采用单光纤连接器技术(如 LC 或 SC)的光纤传输协议搭配使用。
然而,这些长途解决方案可能过于昂贵;特别是,如果有成百上千条链路并需横穿较短的链路距离,费用尤为高昂;这两种情况都是典型的数据中心案例。因此,数据中心通常部署并行光学技术。由于并行收发器每千兆位成本更低,因此基于 MPO 的连接是短距离传输的不错选择。因此,当前人们在选择连接器时并不过多考虑速度,而是更多考察连接器支持的数据通道数量、占用的空间以及对收发器和交换机技术的价格影响。
归根结底,在各种网络设计的推动下,光学收发器和光学连接器的范围正在扩大。超大规模数据中心可以选择实施定制水平极高的光学设计;鉴于这些市场推动者的规模庞大,为应对这种局面,标准机构和 OEM 通常会制定新的标准及开拓新的市场机会。因此,投资和规模引领行业朝着新的方向发展,综合布线设计也在不断发展以满足这些新要求。
了解布线的最新进展,阅读迁移到 400G/800G:第二部分。

Propel™ - 高速光纤平台

企业数据中心解决方案

解决方案
超大规模云数据中心

解决方案
多租户数据中心

解决方案
服务提供商数据中心

深度见解
多模光纤:资料文件
在线资源库
高速迁移库

规格信息
OSFP MSA

规格信息
QSFP-DD MSA
规格
QSFP-DD硬件


乍一看,似乎非常多的潜在基础设施合作伙伴争相与您建立业务关系。愿意向您出售光纤和连接服务的提供商从不缺乏。但是,当仔细观察并思考对网络的长期顺利运行至关重要的各项因素时,选择范围开始缩小。这是因为人们需要的不仅仅是光纤和连接,更要寻求推动网络发展。而这正是康普脱颖而出的关键。
性能可靠:40多年来,康普一直不懈推动创新及提升性能—我们的单模TeraSPEED®光纤比首项OS2标准的出台时间提前三年,我们的开创性宽带多模催生了OM5多模。如今,我们的端到端光纤和铜缆解决方案以及AIM智能技术支持要求最苛刻的应用,为您提供带宽、配置选项和超低损耗性能,帮助您轻松实现增长。
敏捷性和适应性: 我们的模块化产品组合使您能够快速轻松地满足持续变化的网络需求。单模和多模、预端接电缆组件、高度灵活的接插板、模块化组件、光纤MPO连接(8、12、16和24芯)、极小尺寸双工和并行连接器。康普让您保持高速、敏捷,随时把握机会。
面向未来: 随着您从100G迁移到400G、800G及更高版本,我们的高速迁移平台提供了清晰、平稳的路线和方法,以提高光纤密度、加快通道速度及提供新的拓扑。在不更换综合布线基础设施的情况下折叠网络层,随着需求的演变迁移到速度更快、延迟更短的服务器网络。一个强大而又敏捷的平台,带您走向未来。
可靠性保证:康普做出应用保障,保证当前设计的链路将在未来几年满足您的应用需求。我们通过全方位生命周期服务计划(规划、设计、实施和运营)、全球现场应用工程师团队以及康普一贯秉承的25年保修服务来践行这项承诺。
全球可用性和本地支持:康普全球业务覆盖范围包括横跨六大洲的制造、分销和本地技术服务,共有20,000名热情的专业服务人员。随时随地为您提供服务,满足您的需求。我们的全球合作伙伴网络确保您享受认证设计人员、安装人员和集成商提供的专业服务,推动您的网络持续向前发展。





1 2020年度数字趋势;thenextweb.com
2 超大规模的黄金时代;数据中心杂志;2020年11月30日
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5《数据中心一体化最佳实践:设计仓储级计算机》第三版Luiz André Barroso、Urs Hölzle和Parthasarathy Ranganathan Google LLC。Morgan & Claypool出版社 第27页
6 LightCounting presentation for ARPA-E conference - 2019年10月.pdf (energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9Andy Bechtolsheim,Arista,OFC '21